KNN (K-Nearest Neighbors) เป็น โมเดลสำหรับการจัดกลุ่ม (Classification) หรือ การประมาณค่า (Regression) ที่อยู่ในกลุ่ม Machine Learning แบบ Supervised Learning โดยมันทำงานโดยดู “เพื่อนบ้านที่ใกล้ที่สุด” (Nearest Neighbors) เพื่อทำนายผลลัพธ์ของจุดข้อมูลใหม่
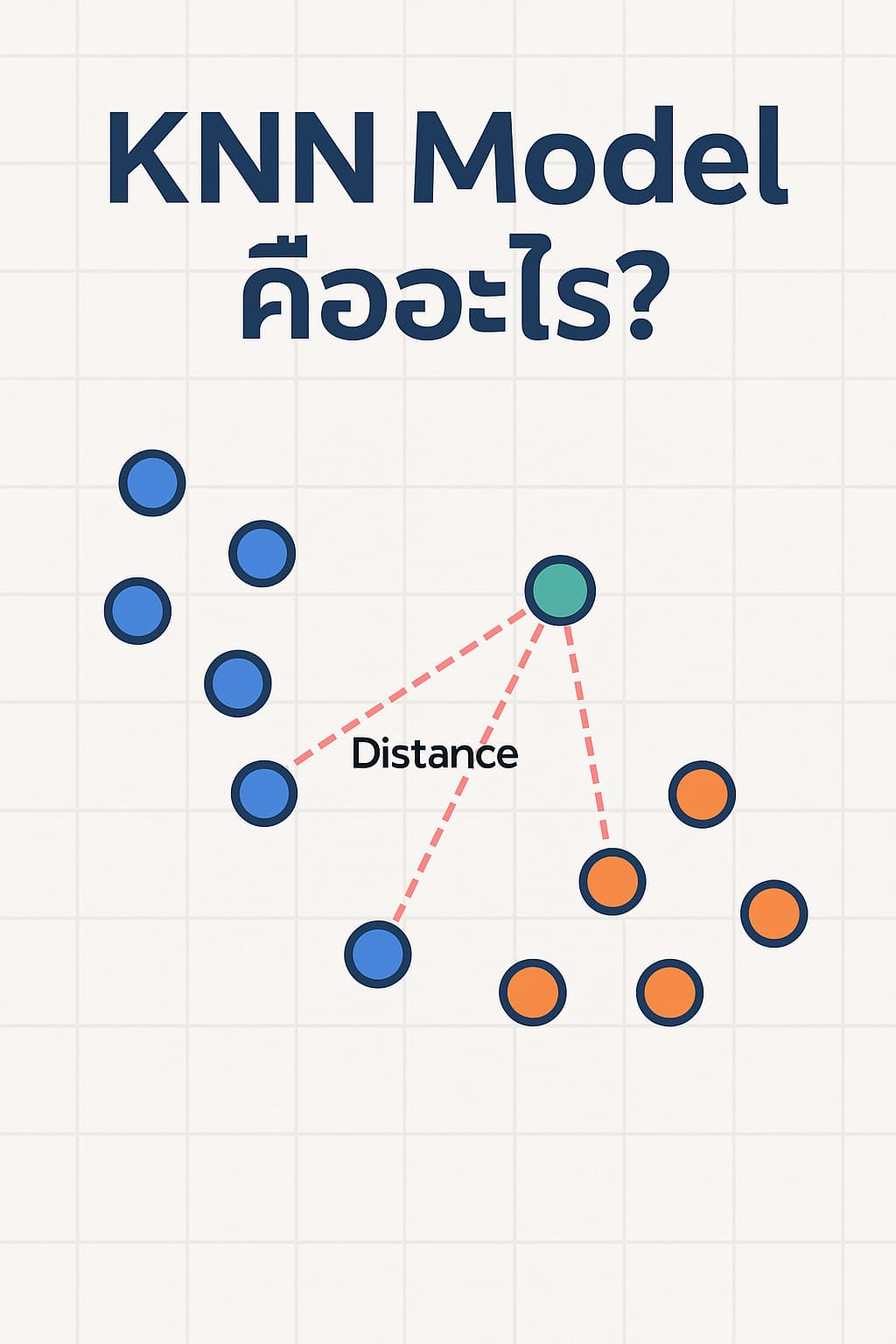
 หลักการทำงานของ KNN
หลักการทำงานของ KNN
- กำหนดค่า K (จำนวน “เพื่อนบ้าน” ที่ใกล้ที่สุด เช่น K=3)
- คำนวณระยะห่าง (เช่น Euclidean Distance) ระหว่างข้อมูลใหม่กับข้อมูลในชุดฝึกสอน (Training Set)
- เลือก K จุดข้อมูลที่ใกล้ที่สุด
-
- ถ้าเป็น Classification → ดูว่าจำนวนมากสุดเป็นคลาสไหน → เลือกค่านั้น
- ถ้าเป็น Regression → เฉลี่ยค่าของเพื่อนบ้าน → ใช้ค่านั้นเป็นคำตอบ
วิธีการคำนวณระยะห่าง (Distance)
ตัวอย่างเช่น Euclidean Distance:
d(p, q) = \sqrt{(p_1 - q_1)^2 + (p_2 - q_2)^2 + \dots + (p_n - q_n)^2}
หรืออาจใช้ Manhattan, Minkowski, Cosine ฯลฯ ก็ได้ ขึ้นอยู่กับปัญหา
 ตัวอย่าง
ตัวอย่าง
ปัญหา:
เรามีข้อมูลของนักเรียน 3 คน โดยรู้คะแนนคณิตศาสตร์และภาษาอังกฤษ พร้อมกับเกรด
| คณิต | อังกฤษ | เกรด |
|---|---|---|
| 90 | 80 | A |
| 60 | 70 | B |
| 70 | 60 | B |
ถ้ามีนักเรียนใหม่สอบได้ 80 (คณิต) และ 75 (อังกฤษ) → KNN จะเทียบกับคนอื่น แล้วดูว่าใครใกล้สุด (ใช้ระยะห่าง) แล้วตัดสินใจให้เกรดเหมือนเพื่อนบ้าน
 ข้อดีของ KNN
ข้อดีของ KNN
- เข้าใจง่าย
- ไม่ต้องเทรนโมเดล (Lazy Learning)
- ใช้ได้ทั้ง Classification และ Regression
 ข้อเสียของ KNN
ข้อเสียของ KNN
- ช้าเมื่อข้อมูลเยอะ (เพราะต้องคำนวณทุกจุด)
- แพ้ Noise หรือข้อมูลที่ไม่สมดุล
- ต้องปรับเลือกค่า K และวิธีการวัดระยะให้เหมาะสม
การใช้งานในภาษา Python (ตัวอย่าง)
from sklearn.neighbors import KNeighborsClassifier
# ข้อมูลตัวอย่าง
X = [[90, 80], [60, 70], [70, 60]]
y = ['A', 'B', 'B']
# โมเดล
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X, y)
# ทำนาย
new_student = [[80, 75]]
print(model.predict(new_student)) # ผลลัพธ์: ['A'] หรือ ['B']
