แหล่งข้อมูลเหล่านี้นำเสนอขั้นตอนการสร้างและทำงานของโครงข่ายประสาทเทียม โดยเน้นไปที่การประมวลผลรูปภาพและการรู้จำตัวเลข แหล่งแรกอธิบายการเขียนโปรแกรมด้วยภาษา Python ตั้งแต่พื้นฐานของนิวรอนตัวเดียว ไปจนถึงกระบวนการย้อนกลับ (Backpropagation) เพื่อปรับปรุงค่าความแม่นยำด้วยตนเอง ในขณะที่อีกแหล่งเน้นการนำเสนอภาพเชิงทัศน์ของโครงข่ายประสาทแบบคอนโวลูชัน (CNN) ที่แสดงให้เห็นการดึงคุณลักษณะเด่นผ่านชั้นกรองข้อมูลและการลดทอนขนาดภาพ ทั้งสองวิดีโอแสดงให้เห็นว่าระบบสามารถเรียนรู้จากข้อมูลชุดตัวเลขเขียนด้วยมือและสินค้าแฟชั่นจนสามารถพยากรณ์ผลลัพธ์ ได้อย่างแม่นยำ สรุปได้ว่าเนื้อหาดังกล่าวช่วยให้เข้าใจทั้งในด้านการเขียนโค้ดคณิตศาสตร์ เบื้องหลังและการทำงานเชิงโครงสร้างของปัญญาประดิษฐ์อย่างเป็นระบบ
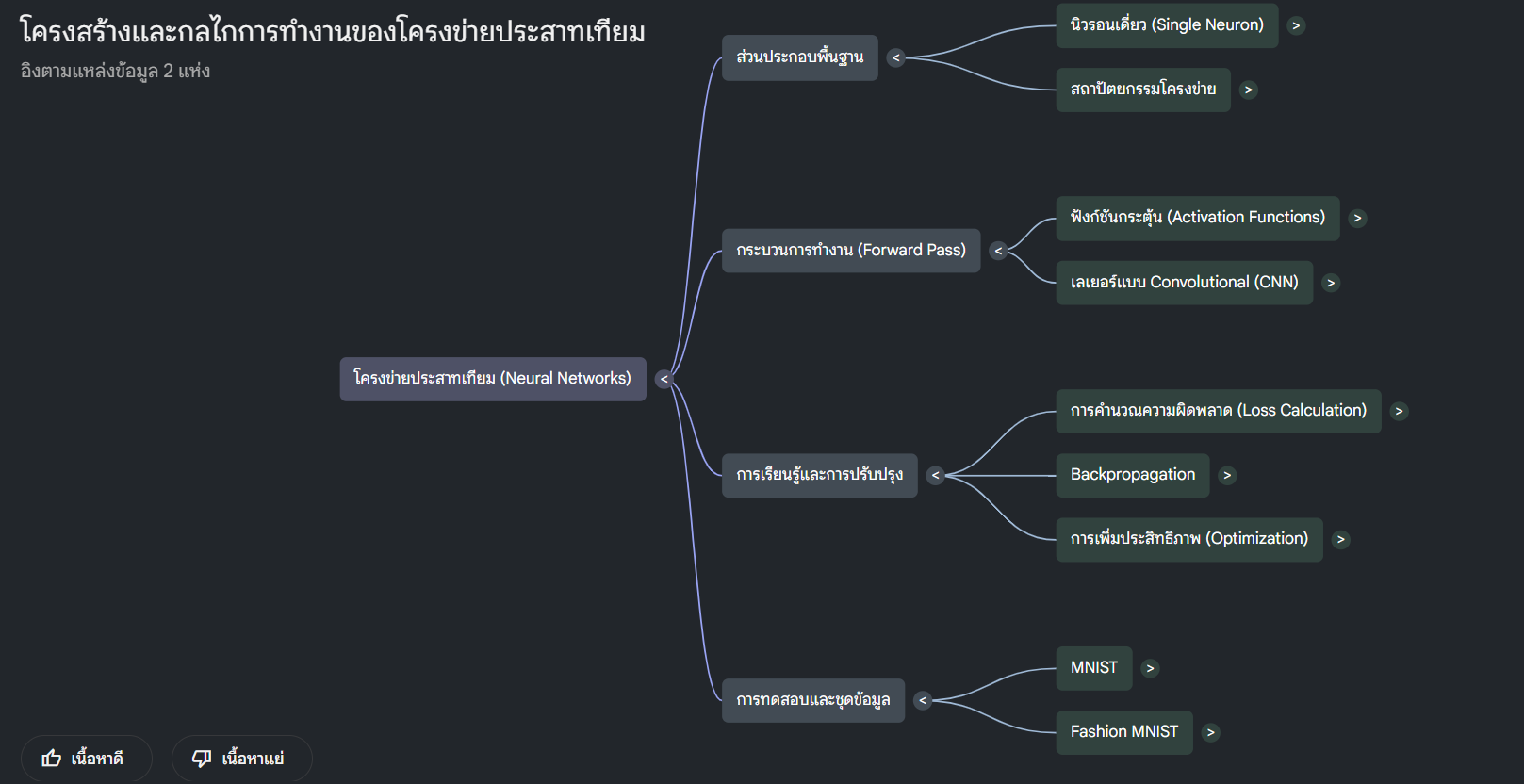
การทำงานพื้นฐานของโครงข่ายประสาทเทียม (Neural Network) ที่สร้างขึ้นเองมีขั้นตอนหลักที่เริ่มต้นจากการคำนวณในระดับเซลล์ประสาทไปจนถึงการเรียนรู้เพื่อปรับปรุงตัวเอง ดังนี้:
- โครงสร้างของเซลล์ประสาทเดี่ยว (Individual Neuron)
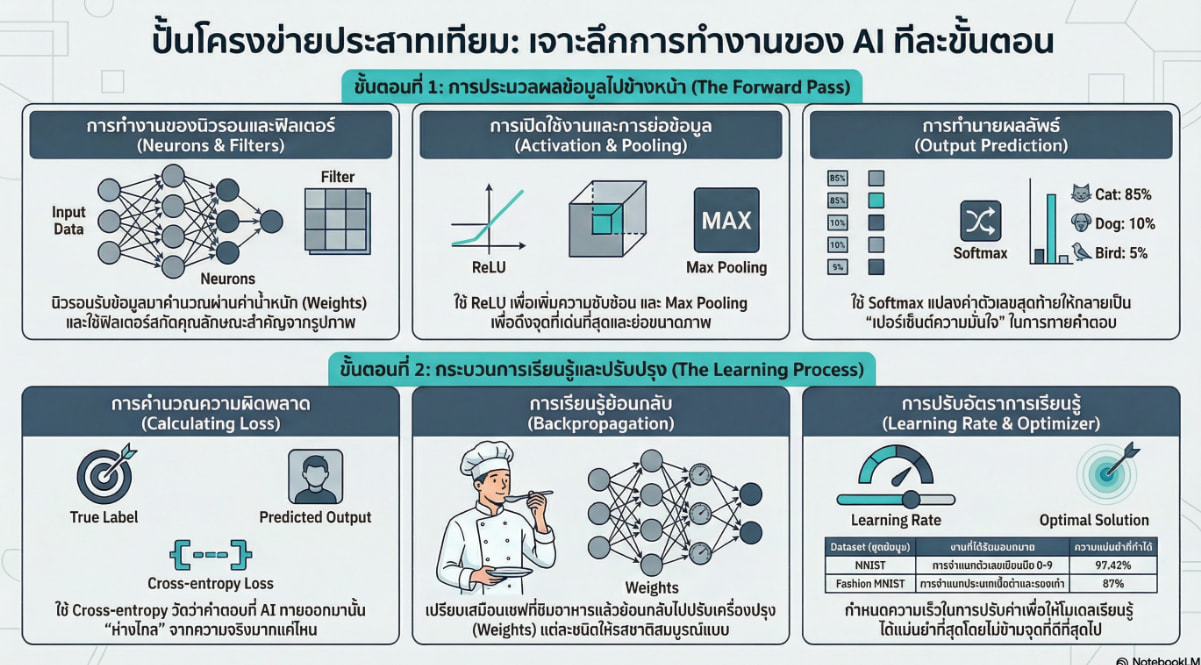
ในระดับพื้นฐานที่สุด เซลล์ประสาทหนึ่งเซลล์จะรับข้อมูลเข้า (Inputs) หลายทาง โดยแต่ละการเชื่อมต่อจะมี ค่าถ่วงน้ำหนัก (Weights) และมีการเพิ่ม ค่าอคติ (Bias) เข้าไป ผลลัพธ์ที่ได้คือ ผลรวมแบบถ่วงน้ำหนัก (Weighted Sum) ของข้อมูลเข้าทั้งหมด ซึ่งในทางปฏิบัติจะใช้พีชคณิตเชิงเส้น (Linear Algebra) เช่น การทำ Dot Product เพื่อให้คำนวณได้รวดเร็วขึ้นในบรรทัดเดียว
- การเพิ่มฟังก์ชันกระตุ้น (Activation Functions)
เพื่อให้โครงข่ายสามารถเข้าใจข้อมูลที่มีความซับซ้อน (Non-linear) ได้ เราต้องใส่ฟังก์ชันกระตุ้นเข้าไป:
- ReLU (Rectified Linear Unit): ช่วยเปลี่ยนข้อมูลให้มีความไม่เป็นเชิงเส้น เพื่อให้โครงข่ายเรียนรู้รูปแบบที่ซับซ้อนได้ดีขึ้น* Softmax: มักใช้ในเลเยอร์สุดท้ายเพื่อแปลงค่าตัวเลขที่โครงข่ายส่งออกมาให้กลายเป็น การกระจายความน่าจะเป็น (Probability Distribution) ซึ่งบอกว่าโครงข่ายมั่นใจแค่ไหนว่าข้อมูลนั้นอยู่ในคลาสใด
- การส่งข้อมูลไปข้างหน้า (Forward Pass)
ข้อมูลจะถูกส่งผ่านเลเยอร์ต่าง ๆ ของโครงข่ายประสาท โดยแต่ละเลเยอร์จะนำผลลัพธ์จากเลเยอร์ก่อนหน้ามาคำนวณเป็นผลรวมถ่วงน้ำหนักและผ่านฟังก์ชันกระตุ้น ทำซ้ำไปเรื่อย ๆ จนถึงเลเยอร์สุดท้ายเพื่อให้ได้ผลการทำนายออกมา
- การคำนวณความผิดพลาด (Calculating Loss)
เมื่อได้ผลการทำนายแล้ว เราต้องวัดว่าโครงข่ายเดาผิดไปมากน้อยเพียงใด โดยใช้ฟังก์ชันที่เรียกว่า Cross-categorical entropy loss เพื่อคำนวณค่าความสูญเสีย (Loss) หรือความผิดพลาดจากการทำนายนั้น
- การแพร่ย้อนกลับ (Backpropagation)
ขั้นตอนนี้คือหัวใจของการเรียนรู้ โดยเปรียบเทียบเหมือน “ทีมเชฟในครัว” หากรสชาติอาหารผิดเพี้ยน (มี Loss) เราต้องย้อนกลับไปดูว่าเชฟคนไหนใส่ส่วนผสม (Weights) มากหรือน้อยเกินไป:
- ใช้การหาอนุพันธ์ย่อย (Partial Derivatives) เพื่อคำนวณว่าแต่ละค่าถ่วงน้ำหนักส่งผลต่อความผิดพลาดอย่างไร* จากนั้นจึงทำการ ปรับปรุงค่าถ่วงน้ำหนักและค่าอคติ เพื่อให้การทำนายในครั้งหน้าแม่นยำขึ้น
- การหาค่าที่เหมาะสมที่สุด (Optimization)
ในขณะที่ฝึกสอน เราจะใช้ตัวปรับแต่งที่เรียกว่า Optimizer (เช่น SGD) และกำหนด อัตราการเรียนรู้ (Learning Rate) :
- หาก Learning Rate สูงเกินไป โครงข่ายอาจเรียนรู้สะเปะสะปะ* หากต่ำเกินไป อาจใช้เวลานานมากในการเรียนรู้* การฝึกจะทำซ้ำเป็นวงจร: Forward Pass → คำนวณ Loss → Backwards Pass → อัปเดตค่าถ่วงน้ำหนัก จนกว่าโครงข่ายจะมีความแม่นยำที่น่าพอใจ