WeKnora เป็นเฟรมเวิร์กโอเพนซอร์สโดย Tencent ที่ออกแบบมาเพื่อจัดการกับเอกสารที่หลากหลาย (“heterogeneous documents”) และช่วยให้สามารถเข้าใจเนื้อหาเอกสารได้อย่างลึกซึ้ง (deep understanding) พร้อมกับความสามารถในการค้นหาและตอบคำถามตามบริบท (context-aware answers) โดยอาศัยแนวทาง RAG (Retrieval-Augmented Generation) ซึ่งคือการผสมผสานระหว่างการค้นคืนส่วนที่เกี่ยวข้องจากเอกสาร + การสร้างคำตอบผ่านโมเดลภาษาขนาดใหญ่ (LLM)
โครงสร้างหลัก (Architecture & Modules)
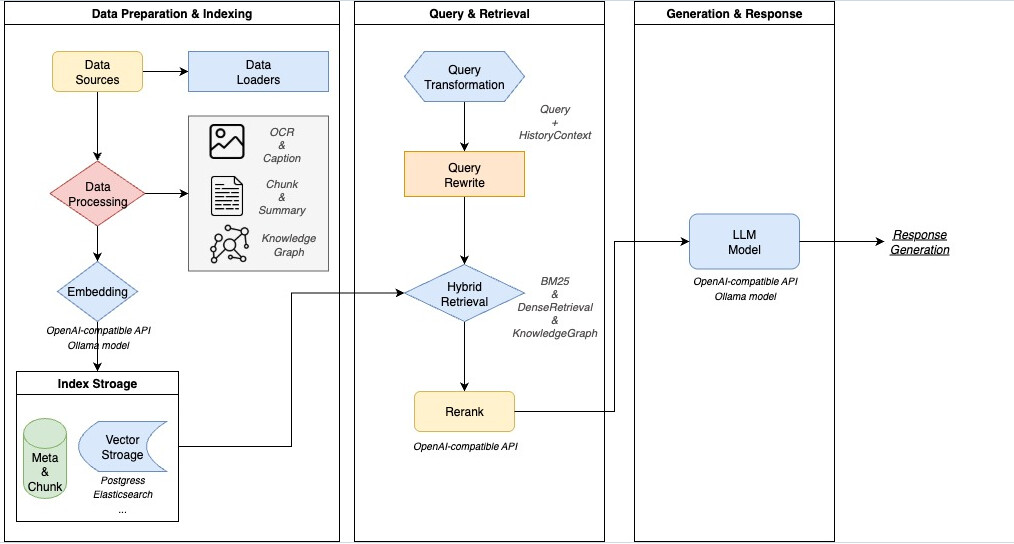
WeKnora ประกอบด้วยหลายส่วนหลัก ๆ โดยแต่ละส่วนสามารถปรับแต่งได้:
| โมดูล | รายละเอียด |
|---|---|
| Preprocessing / Document Parsing | รองรับเอกสารหลายประเภท — PDF, Word, Text, Markdown, รูปภาพ (ภาพที่มี OCR) ฯลฯ เพื่อสกัดข้อความ / โครงสร้างภายในเอกสารออกมาเป็น “semantic view” |
| Embedding / Vector Processing | เปลี่ยนข้อมูลข้อความ (หรือข้อความที่ประมวลผลจาก OCR) เป็นเวกเตอร์ (embeddings) โดยรองรับทั้งโมเดลในเครื่อง (local models) และ API ภายนอก เช่น BGE / GTE ฯลฯ |
| Vector DB / Indexing | จัดเก็บเวกเตอร์และดัชนี (index) สำหรับการค้นหาแบบ semantic / dense retrieval รวมถึงการค้นหาแบบ sparse / keyword-based ด้วย เช่น BM25 |
| Retrieval Engine & Strategies | มีหลายกลยุทธ์ เช่น sparse (keyword / BM25) + dense (vector) + graphRAG ซึ่งรวมองค์ความรู้กราฟ (knowledge graph) ในการเพิ่มคุณภาพการค้นค้นและอันดับผลลัพธ์ (reranking) |
| LLM Inference / Reasoning | เมื่อดึงเนื้อหาที่เกี่ยวข้องมาแล้ว โมเดลภาษา (LLM) จะถูกใช้เพื่อ “เข้าใจบริบทผู้ใช้ + เจตนาผู้ใช้ (user intent)” ตอบคำถาม ทำบทสนทนาหลายก้าว (multi-turn) ใช้ prompt templates, มีโหมดคิด (thinking) และไม่คิด (non-thinking) ฯลฯ |
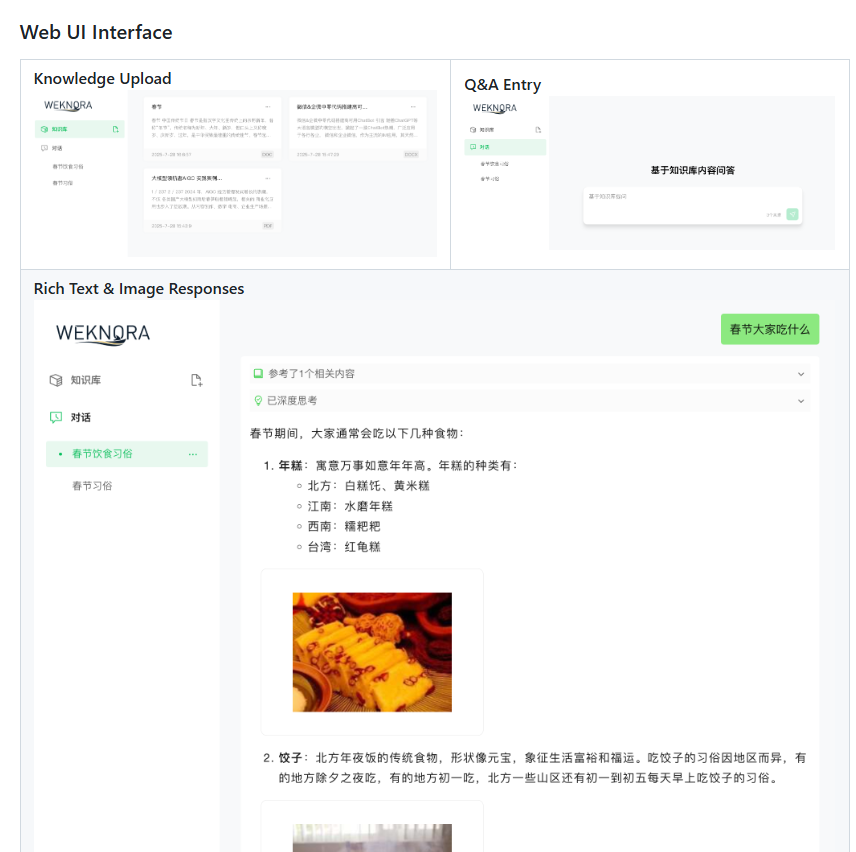
| Web UI + APIs | มีหน้าเว็บสำหรับใช้งาน, อัปโหลดเอกสาร, จัดการฐานความรู้, สร้างคำถาม-คำตอบ, interface สำหรับเรียก API เป็นต้น |
| Deployment & การรักษาความปลอดภัย | รองรับการติดตั้งในเครื่อง (on‐premises) หรือบนคลาวด์ส่วนตัว (private cloud), ควบคุมข้อมูลได้ ส่งผลให้สามารถใช้งานในองค์กรที่ต้องการความปลอดภัยสูงได้ |
ฟีเจอร์เด่น (Key Features)
- ความเข้าใจที่แม่นยำ (Precise Understanding) — โครงสร้างของเอกสาร เช่น หัวข้อ, ย่อหน้า, รูปภาพ, OCR ‒ ทำให้เข้าใจได้ไม่ใช่แค่ข้อความดิบ ๆ
- เหตุผลอัจฉริยะ & ตอบตามบริบท (Intelligent Reasoning & Context-Aware Q&A) — ใช้ LLM เพื่อเข้าใจคำถาม, บริบท และตอบด้วยความเข้าใจเนื้อหาในเอกสารได้ดี
- ความยืดหยุ่น (Flexible Extension) — สามารถปรับโมดูล embedding, retrieval, generation ได้ตามต้องการ; สามารถเปลี่ยนตัว backend (vector DB), เปลี่ยนโมเดลต่าง ๆ ฯลฯ
- ประสิทธิภาพของการค้นหา (Efficient Retrieval) — ใช้กลยุทธ์ผสมผสาน sparse + dense + ความช่วยเหลือจากกราฟความรู้ (knowledge graph) เพื่อได้ผลลัพธ์ที่แม่นยำและเร็วขึ้น
- อินเทอร์เฟซและ API ที่ใช้งานง่าย — มีส่วนติดต่อผู้ใช้ผ่านเว็บ, API มาตรฐาน, การอัพโหลดเอกสาร, การจัดการฐานความรู้, คำถาม-ตอบ ฯลฯ
เคสใช้งาน (Application Scenarios)
WeKnora เหมาะกับหลายกรณีใช้งาน เช่น:
- การจัดการความรู้ในองค์กร
- เก็บเอกสารภายใน เช่น คู่มือ นโยบาย ขั้นตอนปฏิบัติงาน
- ให้พนักงานค้นหาเนื้อหา, ถาม-ตอบได้ทันที ลดเวลาในการค้นหาเอกสาร
- งานวิจัย / Academia
- ค้นบทความวิชาการ, รายงาน, thesis, รูปแบบไฟล์หลายแบบ
- ช่วยในการทบทวนวรรณกรรม (literature review), วิเคราะห์เอกสารจำนวนมาก
- ฝ่ายสนับสนุน / Technical Support
- มีคู่มือผลิตภัณฑ์, เอกสารเทคนิค
- เมื่อลูกค้ามีคำถาม ‒ สามารถค้นเจอคำตอบในเอกสารได้โดยอัตโนมัติ
- กฎหมาย / Compliance
- ดึงเงื่อนไขในสัญญา, นโยบาย กฏระเบียบ
- จัดการความเสี่ยงในการละเมิดข้อบังคับ
- การแพทย์ / การวิเคราะห์ทางคลินิก
- ค้นแนวทางการรักษา, บทความวิจัย, กรณีศึกษา
- ช่วยสนับสนุนการตัดสินใจทางคลินิก
ใช้วัตถุประสงค์และข้อจำกัด
ใช้ทำอะไรได้บ้าง
- สร้างระบบถาม-ตอบจากเอกสาร (Document QA System) ที่ “เข้าใจ” เนื้อหาได้ดีและตอบคำถามได้ตามบริบท
- ค้นหาเอกสาร/ข้อมูลเฉพาะจากฐานเอกสารขนาดใหญ่ โดยใช้การค้นแบบ semantic (ไม่ใช่เฉพาะ keyword)
- จัดการและจัดโครงสร้างเอกสารหลายประเภทให้เป็นระบบ เพื่อให้ง่ายต่อการค้นและใช้งาน
- พัฒนา chatbot ที่สามารถตอบคำถามอิงตามเอกสารภายในองค์กร
- วิเคราะห์เนื้อหา การทำสรุป (summarization) หรือช่วยในการตัดสินใจโดยอาศัยเอกสารหลายแหล่ง
ข้อจำกัด / สิ่งที่อาจต้องพิจารณา
- ความแม่นยำขึ้นกับคุณภาพของเอกสารต้นฉบับ (เช่น ถ้า OCR จากรูปภาพไม่ดี ก็อาจสกัดข้อความผิด)
- ค่าใช้จ่ายและทรัพยากรสำหรับการใช้งาน LLM / embedding / storage (เวกเตอร์ ฐานข้อมูล)
- ต้องตั้งค่าเหมาะสม (configuration) และปรับแต่งโมเดลให้เข้ากับงานเฉพาะ (fine-tuning / prompt design)
- สำหรับบางกรณีอาจมีเรื่องสิทธิความเป็นส่วนตัว (privacy) ถ้าเอกสารเป็นข้อมูลภายในหรือข้อมูลส่วนบุคคล ต้องแน่ใจว่าการ deploy ปลอดภัย
สรุป
WeKnora เป็นเครื่องมือที่ทรงพลังมาก ถ้าคุณต้องการสร้างระบบที่:
- เข้าใจเอกสารหลายประเภท (pdf, word, รูปภาพ ฯลฯ)
- ค้นหา/ตั้งคำถามเกี่ยวกับเอกสารได้โดยไม่จำเป็นต้องรู้คำค้นทางเทคนิค
- มีความสามารถในการให้คำตอบที่มีบริบทและแม่นยำ
ถ้าใช้งานครบทุกโมดูลและตั้งค่าอย่างดี มันสามารถช่วยลดงานซ้ำซ้อน ลดเวลาในการค้นเอกสาร และเพิ่มประสิทธิภาพการทำงานในองค์กรได้เยอะมาก
